Distributed Processing
A key component required in KWIVER to enable the construction of fully elaborated computer vision systems is a strategy for multi-processing by distributing Sprokit pipelines across multiple computing nodes. This a critical requirement since modern computer vision algorithms tend to be resource hungry, especially in the case of deep learning based algorithms which require extensive GPU support to run optimally. KWIVER has been utilized in systems using the `The Robotics Operating System (ROS) <http://www.ros.org>>`_ and Apache Kafka among others.
KWIVER, however, can use a built-in mechanism for constructing multi-computer processing systems, with message passing becoming an integral part of the KWIVER framework. We have chosen to use ZeroMQ for the message passing architecture, because it readily scales from small brokerless prototype systems to more complex broker based architectures that span many dozens of communicating elements.
The current ZeroMQ system focuses on “brokerless” processing, relying on pipeline configuration settings to establish communication topologies. What this means in practice is that pipelines must be constructed in a way that “knows” where their communication partners are located in terms of networking (hostname and ports). While this is sufficient to stand up a number of interesting and useful systems it is expected that KWIVER will evolve to providing limited brokering services to enable more flexibility and dynamism when constructing KWIVER based multi-processing systems.
KWIVER’s multi-processing support is composed of two components:
Serialization
Transport
In keeping with KWIVER’s architecture, both of these are represented as abstractions, under which specific implementations (JSON, Protocol Buffers, ZeroMQ, ROS etc.) can be constructed.
Serialization
KWIVER’s serialization strategy is based on KWIVER’s arrows. There is a serialization arrow for each of the VITAL data types. Then there are implementations for various serialization protocols. KWIVER supports JSON based serialization and binary serialization. For binary serialization, Google’s Protocol Buffers are used. While JSON based serialization makes reading and debugging types like detected_object_set easy, binary serialization is used to serialize data heavy elements like images. As with other KWIVER arrows, providing new implementations supporting other protocols is straightforward.
Constructing a Serialization Algorithm
All serializer algorithms must be derived from the data_serializer
algorithm. All derived classes must implement the deserialize() and
serialize() methods, in addition to the configuration support methods.
The serialize() method converts one or more data items into a
serialized byte stream. The format of the byte stream depends on the
serialization_type being implemented. Examples of serialization types
are json and protobuf.
The serialize() and deserialize() methods must be compatible so
that the deserialize() method can take the output of the serialize()
method and reproduce the original data items.
The serialize() method takes in a map of one or more named data
items and the deserialize() method produces a similar map. It is up
to the data_serializer implementation to define what these names are
and the associated data types.
Basic one element data_serializer implementations usually do not require any configuration, but more complicated multi-input serializers can require an arbitrary amount of configuration data. These configuration parameters are supplied
Serialization and Deserialization Processes
The KWIVER serialization infrastructure is designed to allow the use of multiple cooperating Sprokit pipelines to interact with one another in a multiprocessing environment. The purpose of serialization is to package data in a format (a byte string) that can easily be transmitted or received via a transport. The purpose of the serialization and deserialization processes is to convert one or more Sprokit data ports to and from a single byte string for transmission by a transport process.
The serializer process dynamically creates serialization algorithms based on the ports being connected. A fully qualified serialization port name takes the following form:
process.<group>/<element>
On the input side of serializer process, the fully qualified name is used to group individual data elements. In the following case, the group detections is being created.:
connect from detected_object_reader.detected_object_set to serializer.detections/dos
connect from image_reader.image to serializer.detections/image
On the output side, the <group> (detections in this case) portion of the name is used to connect the entire serialized set (Sprokit’s pipeline handling mechanism will insure synchronization of the elements) on the detections output port:
connect from serializer.detections to transport.serialized_message
Similarly, for a deserializer the input side uses the group name:
connect from transport.serialized_message to deserializer.detections
And the output side presents the deserialized element names:
connect from deserializer.detections/dos to detected_object_writer.dos
connect from deserializer.detections/image to image_writer.image
There are some things worth noting:
The serialized group name is embedded in the serailized “packet”. This allows the serializer and deserializer to validate that the the serialized output and input match up. Connecting a serializer output port group to a deserializer input port different_group will result in an error.
A single serializer can have individual elements connected to different input groups. This will simply create multiple group output ports.Similarly a deserializer can have multiple groups on the input side – the individual elements for both groups will appear on the output side (with the appropriate group name in the port name).
serializer/deserializer process details
The serializer process always requires the serialization_type config entry. The value supplied is used to select the set of data_serializer algorithms. If the type specified is json, then the data_serializer will be selected from the ‘serialize-json’ group. The list of data_serializer algorithms can be displayed with the following command
plugin_explorer --fact serialize
Transport Processes
KWIVER’s transport strategy is structured as Sprokit end-caps (the needs and requirements for the transport implementations are somewhat dependent on Sprokit’s stream processing implementation and so don’t lend themselves to implementation as KWIVER arrows). The current implementation focuses on a one-to-many and many-to-one topologies for VITAL data types.
Transport processes take a serialized message (byte buffer) and interface to a specific data transport. There are two types of transport processes, send and receive. The send type processes take the byte buffer from a serializer process and put it on the transport. The receive type processes take a message from the transport and put it on the output port to go to a deserializer process.. The port name for both types of processes is “serialized_message”.
The canonical implementation of the Sprokit transport processes is based on ZeroMQ, specifically ZeroMQ’s PUB/SUB pattern with REQ/REP synchronization.
The Sprokit ZeroMQ implementation is contained in two Sprokit processes, zmq_transport_send_process and zmq_transport_receive_process:
zmq_transport_send_process
-
class zmq_transport_send_process : public sprokit::process
End cap that publishes incoming data on a ZeroMQ PUB Socket.
\process This process can be used to connect separate Sprokit pipelines to one another in a publishi/subscribe framework. This process accepts serialized byte strings from serializer_process and transmits them on a ZeroMQ PUB socket at the specified port.
The process can be optionally configured to wait for an expected number of subscribers before it begins publishing or it can begin publishing immediately. Use these options to control whether subscribers see a consistent amount of data. Waiting to publish might be used when a data source is a directory of images, while publishing immediately might be used when the data source is a live video feed.
The PUB/SUB mechanism makes use of two ports. The actual PUB/SUB socket pair is created on the port specified in the configuration. One above that port is used to handle subscription handshaking.
\iports
\iport{serialized_message} the incoming byte string to publish.
\configs
\config{port} the port number to publish on.
\config{expected_subscribers} the number of subscribers that must connect before publication commences.
-
class priv
-
class priv
zmq_transport_receive_process
-
class zmq_transport_receive_process : public sprokit::process
End cap that subscribes to incoming data on a ZeroMQ SUB Socket and outputs it on a Sprokit byte string port.
\process This process can be used to connect separate Sprokit pipelines to one another in a publishi/subscribe framework. This process accepts serialized byte strings from a ZeroMQ SUB socket and pushes it to a serializer_process for deserialization into a Sprokit pipeline.
The PUB/SUB mechanism makes use of two ports. The actual PUB/SUB socket pair is created on the port specified in the configuration. One above that port is used to handle subscription handshaking.
The process can be optionally configured to listen to multiple publishers. It will connect to each publisher starting at the specified port using port for PUB/SUB and port+1 for synchronization. A subsequent publisher will be connected at port+2 and so on.
\iports
\iport{serialized_message} the incoming byte is sent to a serializer process here.
\configs
\config{port} the port number to subscribe on.
\config{num_publishers} the number of publishers that must be connected to subscription commences.
\config{connect_host} The name of the host to connect to. May be a DNS name or an IP address.
-
class priv
-
class priv
Distributed Pipelines Examples
To demonstrate the use of Sprokit’s ZeroMQ distributed processing capabilities, we’ll first need some simple Sprokit pipeline files. The first will generate some synthetic detected_object_set data, serialize it into Protocol Buffers and transmit the result with ZeroMQ. Here is a figure that illustrates the pipeline
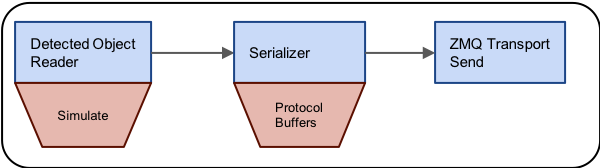
And here is the actual .pipe file that implements it:
process sim :: detected_object_input
file_name = none
reader:type = simulator
reader:simulator:center_x = 100
reader:simulator:center_y = 100
reader:simulator:dx = 10
reader:simulator:dy = 10
reader:simulator:height = 200
reader:simulator:width = 200
reader:simulator:detection_class = "simulated"
# --------------------------------------------------
process ser :: serializer
serialization_type = protobuf
connect from sim.detected_object_set to ser.dos
# --------------------------------------------------
process zmq :: zmq_transport_send
port = 5560
connect from ser.dos to zmq.serialized_message
To receive the data, we’ll create another pipeline that receives the ZeroMQ data, deserializes it from the Protocol Buffer container and then writes the resulting data to a CSV file. This pipeline looks something like this:
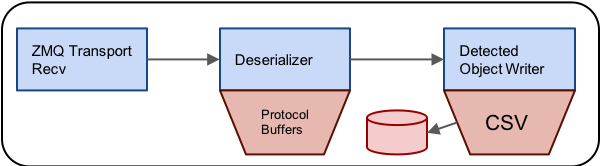
The actual .pipe file looks like this:
process zmq :: zmq_transport_receive
port = 5560
num_publishers = 1
# --------------------------------------------------
process dser :: deserializer
serialization_type = protobuf
connect from zmq.serialized_message to dser.dos
# --------------------------------------------------
process sink :: detected_object_output
file_name = received_dos.csv
writer:type = csv
connect from dser.dos to sink.detected_object_set
We’ll use kwiver runner to start these pipelines. First, we’ll start the send pipeline:
kwiver runner test_zmq_send.pipe
In a second terminal, we’ll start the reciever:
kwiver runner test_zmq_receive.pipe
When the receiver is started, the data flow will start immediately. At the end of execution the file recevied_dos.csv should contain the transmitted, synthesized detected_object_set data.
Multiple Publishers
With the current implementation of the ZeroMQ transport and Sprokit’s dynamic configuration capabilities, we can use these pipelines to create more complex topologies as well. For example, we can set up a system with multiple publishers and a receiver that merges the results. Here is a diagram of such a topology:
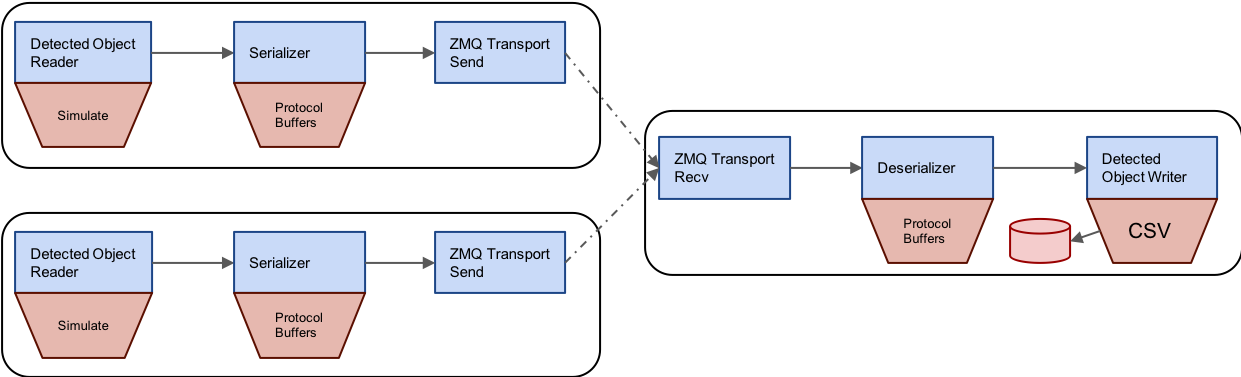
We can use the same .pipe files by reconfiguring the pipeline on the command line using kwiver runner. Here’s how we’ll start the first sender. In this case we’re simply changing the detection_class configuration for the simulator so that we can identify this sender’s output in the resulting CSV file:
kwiver runner test_zmq_send.pipe --set sim:reader:simulator:detection_class=detector_one
In another terminal we can start a second sender. In this case we also change the detection_class configuration and we change the ZeroMQ port to be two above the default port of 5560. This leaves room for the synchronization port of the first sender and sets up the two senders in the configuration expected by a multi-publisher receiver:
kwiver runner test_zmq_send.pipe --set sim:reader:simulator:detection_class=detector_two --set zmq:port=5562
Finally, we’ll start the receiver. We’ll simply change the num_publishers parameter to 2 so that it connects to both publishers, starting at port 5560 for the first and automatically adding two to get to 5562 for the second:
kwiver runner test_zmq_recv.pipe --set zmq:num_publishers=2
Multiple Subscribers
In a similar fashion, we can construct topologies where multiple subscribers subscribe to a single publisher. Here is a diagram of this topology:
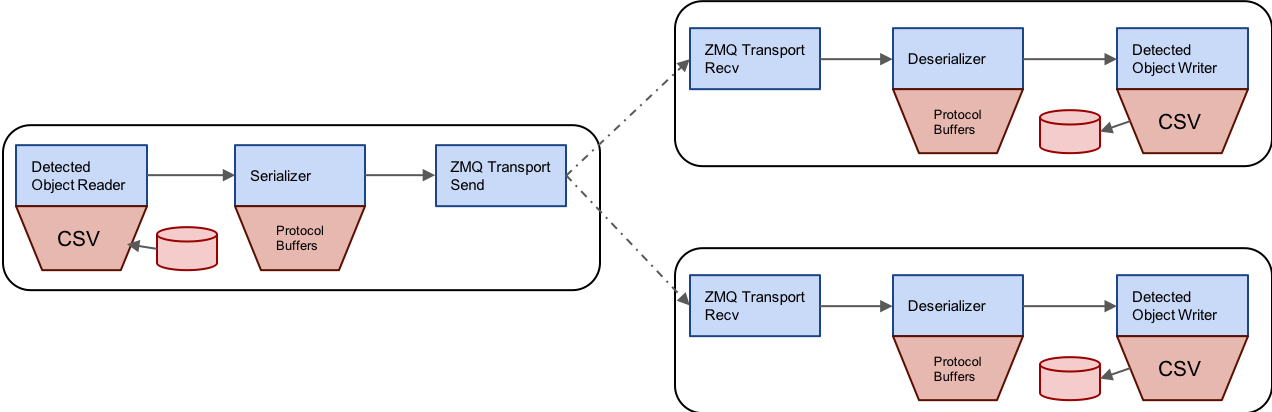
First we’ll start our publisher, reconfiguring it to expect 2 subscribers before starting:
kwiver runner test_zmq_send.pipe --set zmq:expected_subscribers=2
Then, we’ll start our first subscriber, changing the output file name to received_dos_one.csv:
kwiver runner test_zmq_recv.pipe --set sink::file_name=received_dos_one.csv
Finally, we’ll start out second subscriber, this time changing the output file name to received_dos_two.csv:
kwiver runner test_zmq_recv.pipe --set sink::file_name=received_dos_two.csv
Worked examples of these pipelines using the TMUX terminal multiplexor can be found in test_zmq_multi_pub_tmux.sh and test_zmq_multi_sub_tmus.sh in the sprokit/tests/pipelines of the KWIVER repository.